December 12, 2025•10 min read
Ranking Today's AI Literature Search Engines: A Data-Driven Comparison
A methodical assessment of how five leading AI search engines perform on a standardized research question.
A methodical assessment of how five leading AI search engines perform on a standardized research question.
At moara.io, we routinely evaluate emerging research tools as part of our product strategy – particularly when deciding which search engines to integrate or prioritize. Over time, we developed an efficient internal benchmarking process that we find informative. Today, we're sharing that process publicly, along with the results from our most recent comparison.

This analysis focuses solely on search quality, not UI / UX, summaries, writing features, or downstream functionality.
AI literature search tools are becoming increasingly popular. Many offer overlapping features, while others cater to different stages of the research lifecycle. Despite this growing ecosystem, there remains very little structured, transparent benchmarking of the core task researchers care about most: How well does the tool find relevant, high-quality research papers?
Our goal was not to evaluate technical architectures or LLM design decisions – that work is covered extensively by others like Aaron Tay. Instead, we wanted to apply a simple, consistent, and replicable process to compare outputs across tools.
We assessed five of the most widely used AI literature search engines:
These tools differ significantly in scope. Some are pure search engines (e.g., Scholar Labs). Others include broad writing and workflow features (e.g., SciSpace). For this study, we evaluated only the search results themselves.
Our methodology was intentionally simple:
Although simple, the process required extensive manual cleaning. Many tools lack consistent metadata fields, leading to hours of reconciliation to ensure a fair comparison.
Some existing "white papers" in this area use complex multi-query scoring systems to arrive at comparative rankings. However, greater complexity often enables unintentional bias – or, in some cases, deliberate marketing. To illustrate: a well-known (unnamed) example indicates only 2/10 Google Scholar results are relevant to the topic being searched – a conclusion we found far-fetched. Indeed, the methodology of the paper was difficult to interpret.
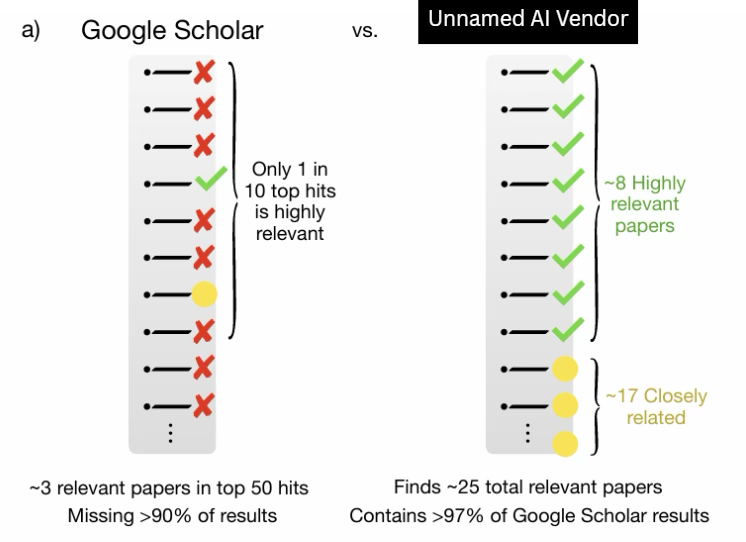
By keeping the process simple and transparent – one query, top 10 results – we avoided methodological adjustments that could advantage one tool over another.
Nonetheless, the consistency of the results across all three models – and in terms of our own conclusions – suggests the results contain meaningful information.
The ranking was remarkably consistent:
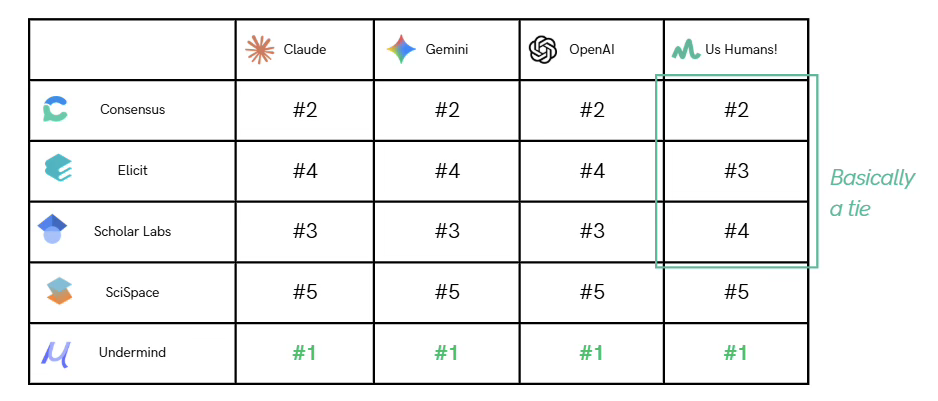
Across every evaluation dimension, Undermind surfaced:
Average citation count exceeded 1,000, and the average publication year was 2018.
Performed well across relevance and recency, and was ranked second by all three general LLMs and us.
Solid results, but with more working papers and less methodological diversity.
Frequently returned older papers and more bottom-up modeling approaches (CGE/IAM), but with high topical relevance. We ranked Elicit #3 over Scholar Labs.
Showed several concerning patterns:
These issues produced the weakest overall performance.
One unexpected finding was the degree to which the selections of methodologies shaped the quantitative results surfaced by each engine.
This is not a judgment about which approach is "better." Instead, it calls out the importance of:
Researchers relying on a single search engine may unintentionally inherit the methodological biases of that system.
Based on the quantitative estimates across all engines (using one estimate per paper and excluding extreme or scenario-specific outliers), the median projected global GDP loss from climate change is approximately 3-4% by 2100.
moara.io is not a search engine. Our goal is not to replace Google Scholar, Undermind, Consensus, or any other discovery tool. Instead, we are building the workflow layer that helps researchers:
During our demonstration, we imported the top 10 results for Undermind directly into moara.io, enriched them with DOI-based metadata, extracted main findings, and retrieved full-text articles. This is precisely the type of workflow that moara.io is designed to support – particularly for large reviews where papers come from a mix of tools, databases, and exports.
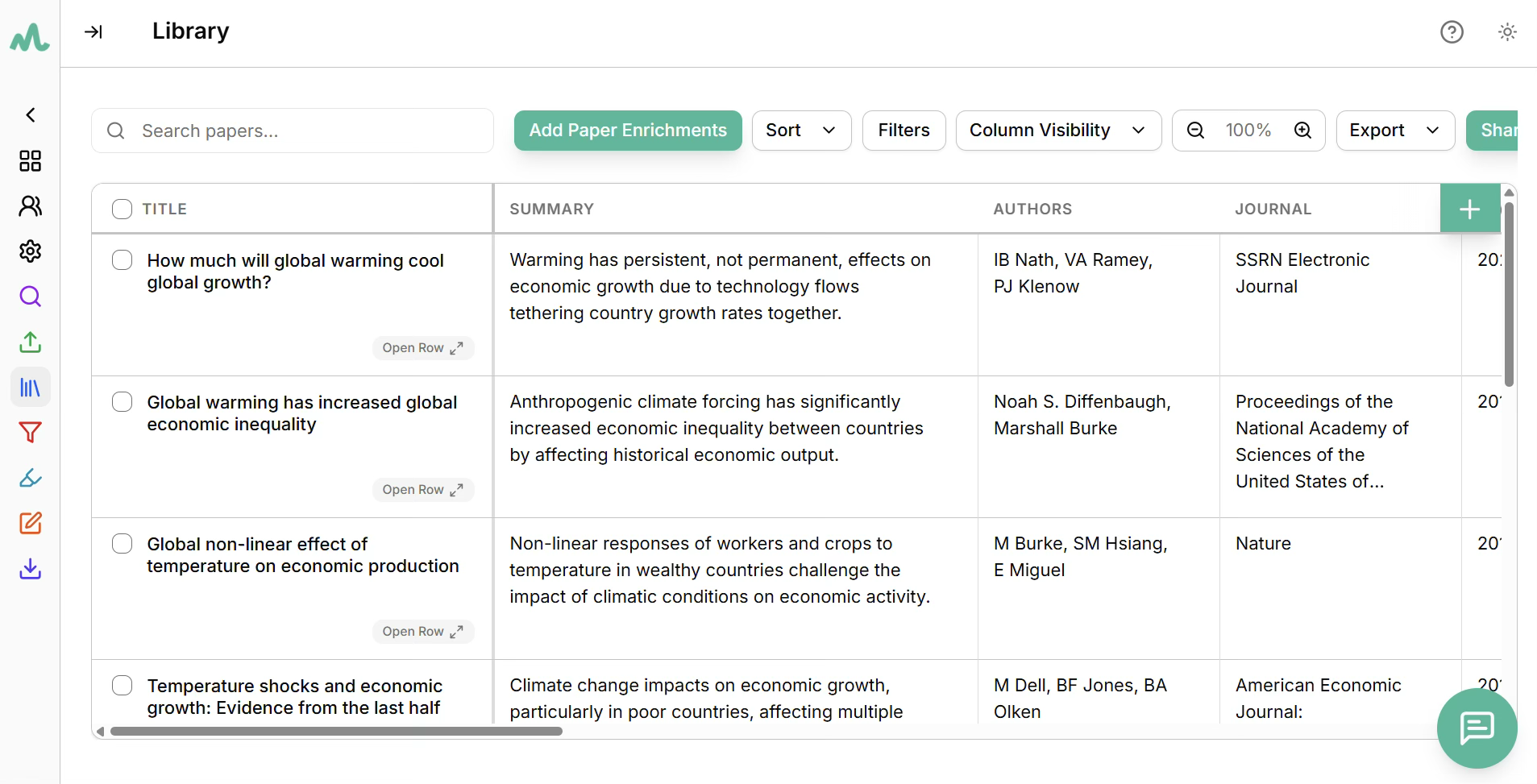
If you'd like access to the moara.io library or the anonymized comparison document for this analysis, feel free to reach out to john@moara.io.
Try moara.io free here: https://app.moara.io/signup